A few years ago, sensitive information was stored in secured data centers or in companies facilities where access was only allowed in the following ways: either through using dedicated VPNs or through strict security mechanisms, as for example firewalls. Nowadays, data is stored very differently due to the existence of massive storage services in the Cloud, such as S3 in AWS. Consequently information should be secured using other perspectives.
Do you believe you are monitoring and identifying any unexpected access to the information stored in the Cloud? If the answer is no, don’t be worried about it! In this blog post we are going to give you some solutions to monitor any unexpected access to your sensitive information.
In the first blog post of this series, we explained how to simulate a real threat in which some credentials were stolen and used to access the S3 service to collect all sensitive information stored. In the second one , we gave some mitigations to prevent anyone from accessing the credentials stored in the AWS Metadata Service.
But what about if credentials were already compromised? Is there a way to identify any unauthorized access to your information stored in S3?
In this blog post we will answer that.
Risks of using a misconfigured S3 Service
Amazon S3 is one of the mostly used cloud storage solutions by companies all over the world for a variety of use cases to power their IT operations. It is defined as an object storage service where you can store any information in what Amazon calls buckets.
Buckets are private by default, but they can sometimes be accidentally misconfigured and made publicly accessible, exposing all of their stored sensitive information to the Internet users. This happened to big companies like Attunity [1], where more than a terabyte of data from its top Fortune 100 customers was leaked. It is not the only way to compromise a bucket, though.
As we stated in the previous blog posts, credentials can be compromised using the Metadata Service or maybe because they were leaked somehow. So, if these compromised credentials have permissions to access S3, all the accessible information should be considered as compromised too.
With these considerations in mind, we have built a detection mechanism to monitor any unexpected access to our sensitive objects stored in a S3 bucket. Let’s go into further detail!
Monitoring architecture overview
As you can see in the image below, we have created a bucket for testing purposes in an AWS account with some banking information stored in CSV files and some innocuous files (goat.png).
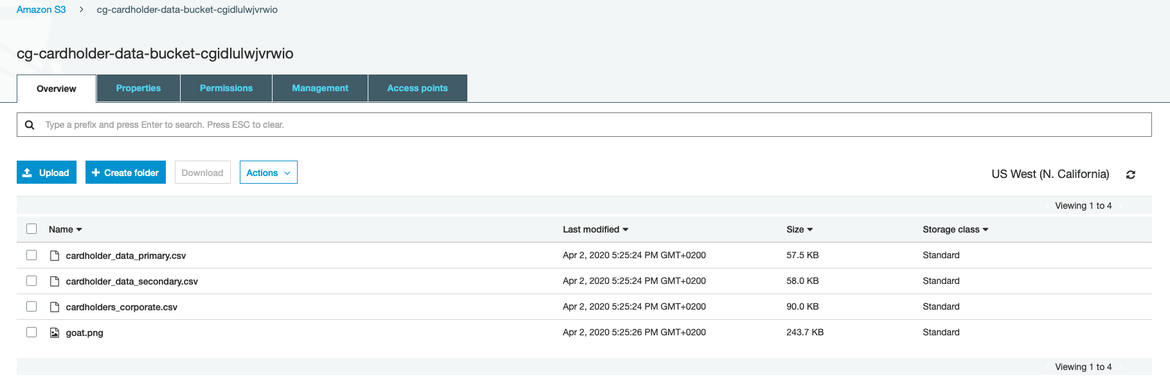
S3 bucket to monitor
Our goal is to notify any access from an unknown origin to the files with cardholder information.
In short, we need to trace all operations to this bucket and notify somehow if any of the sensitive files is accessed. In the following diagram, you can see the strategy to reach this goal using different AWS services:
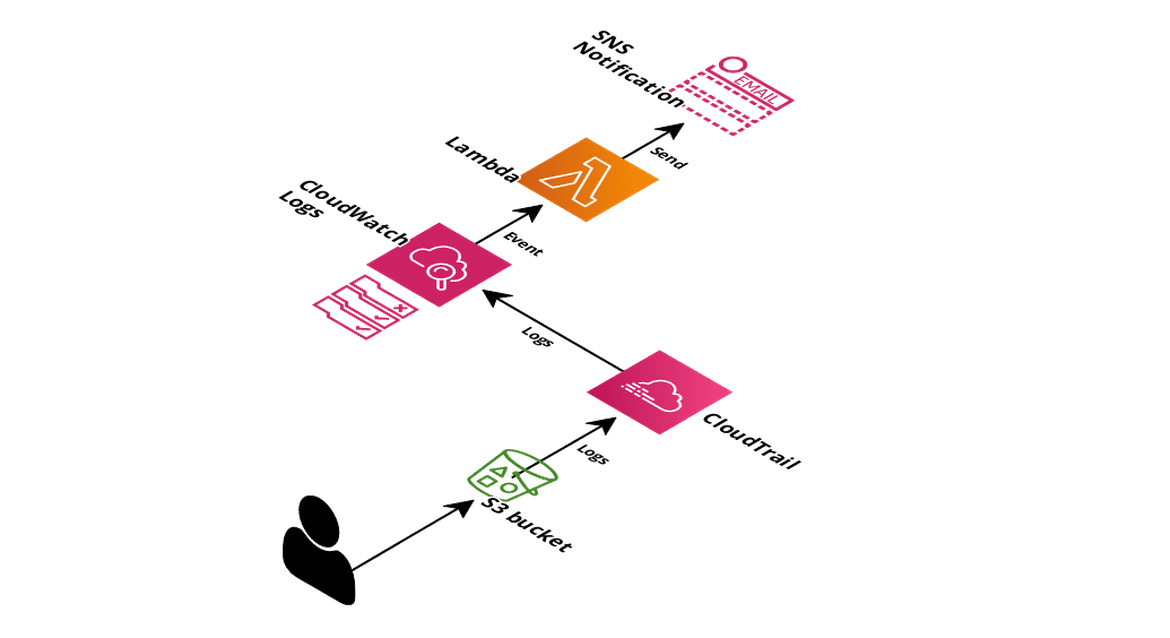
Solution schema
Firstly, logs will be enabled in the monitored S3 bucket and sent to CloudWatch Logs through CloudTrail. At this point, access logs to this S3 bucket will be stored in a Log Group into the CloudWatch Logs service.
Then, a rule will be configured in CloudWatch Logs to identify any access to our monitored S3 bucket, and will trigger a Lambda function if found. This Lambda function will consider some conditions to determine which accesses are considered unauthorized. In this case a notification will be sent using SNS service.
Let’s cover the whole process in detail.
Monitoring S3 Buckets
We need to trace any activity that is happening in our monitored bucket. This will be achieved thanks to enabling CloudTrail logs in our monitored bucket by creating a new trail.
Trails can be enabled in all regions, but in this example we are going to monitor only our region, which is “us-west-1”. Don’t forget to enable the trail setting “Logging”.
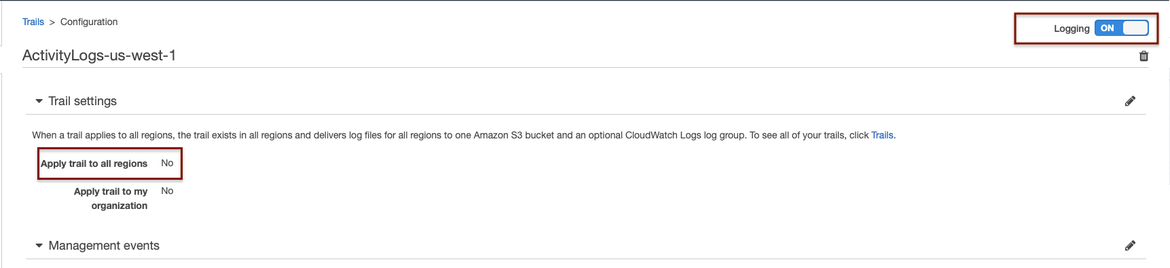
Newly-created CloudTrail trail
In the Data Events section, we will configure the trail to log any activity (read and write) happening in our targeted bucket (the one named “cg-cardholder-data-bucket-cgidlulwjvrwio”):
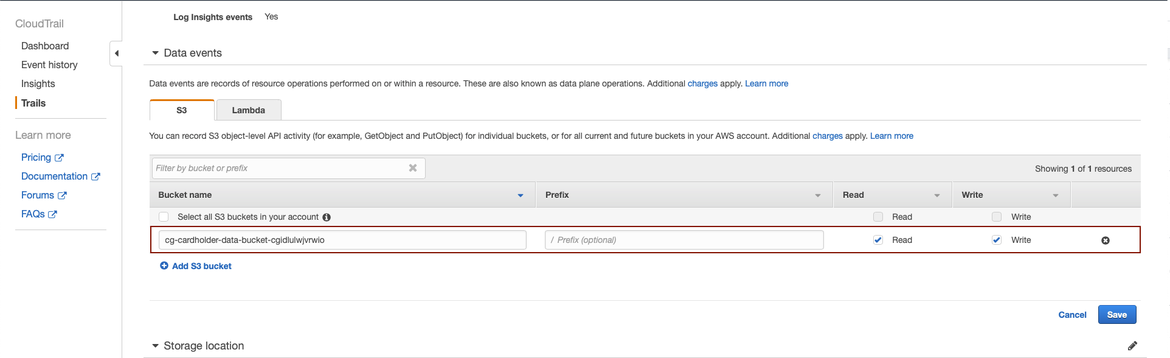
Enabling S3 logs in newly-created trail
After enabling logs on the S3 bucket, we have to configure a storage location where they will be processed. In our case, we will send all the generated traces to a specific Log Group in CloudWatch Logs.
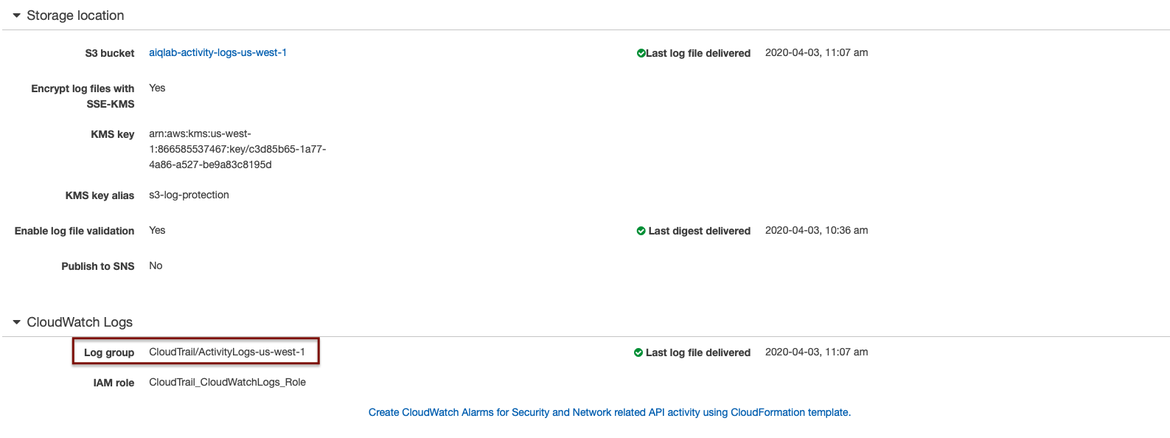
Sending CloudTrail logs to CloudWatch Logs
If the process is completed successfully, all access logs to our S3 bucket should be found in the CloudWatch service through the “Activity-Logs-us-west-1” Log Group:

CloudWatch Logs Log Group
Once logs are stored into the corresponding LogGroup, it is necessary to create a rule that will trigger an action when a log is received.
If you only want to monitor accesses to a defined key or bucket, it is possible with a rule specifying the bucket and the key, and configuring a corresponding SNS topic as a Target where notifications will be sent.
In the particular case we are sharing, to avoid receiving unnecessary notifications, we are going to process the log using a Lambda function to define some specific conditions about when notifications should be sent. Additionally, we will be able to monitor multiple files with the same rule.
In a nutshell, we are going to create a rule to trigger a function call to a Lambda function called “LogS3DataEvents” every time a “GetObject” event is raised in our bucket.
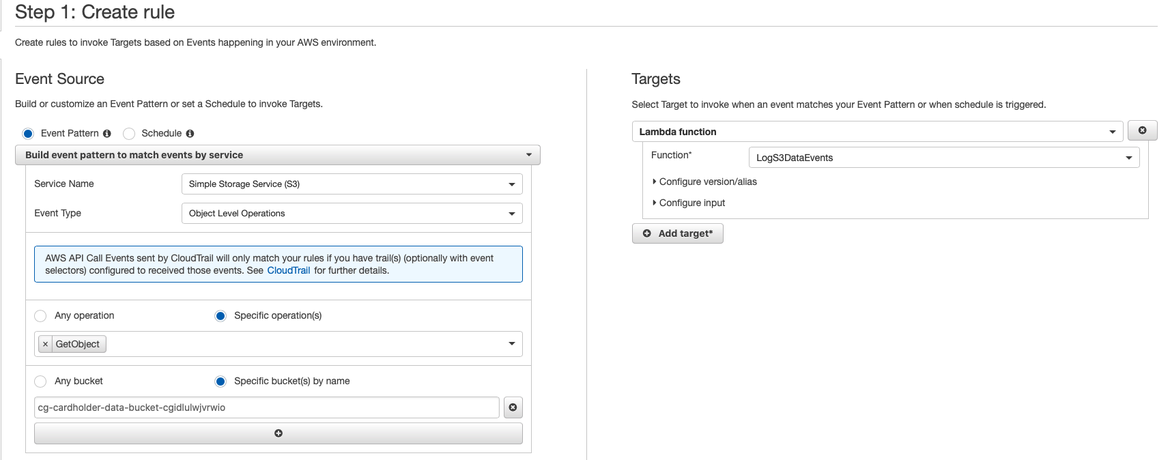
CloudWatch Logs monitoring rule
This Lambda function will process logs and decide under which conditions access is considered unauthorized. Let’s take an even closer look at it.
Processing the logs
After all of the above, now is the time to create the Lambda function for processing the logs. You will need to go to the Lambda service and create a new function from scratch as it is shown below:
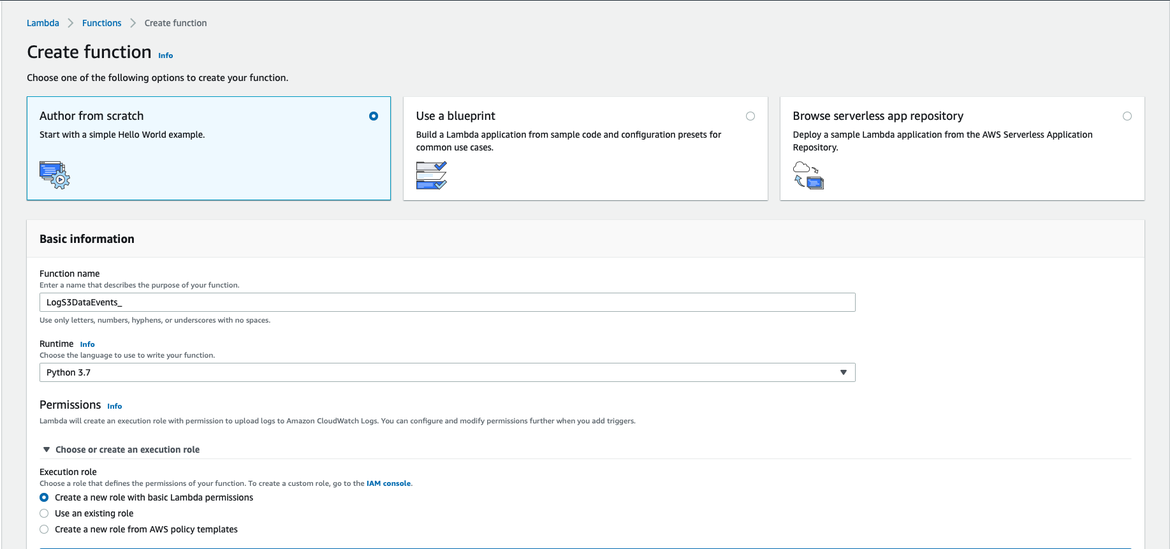
Newly-created Lambda function
Once created, if the Lambda function was successfully configured in the CloudWatch rule as it has been described, a trigger should be shown, displaying that CloudWatch Events is triggering our Lambda.
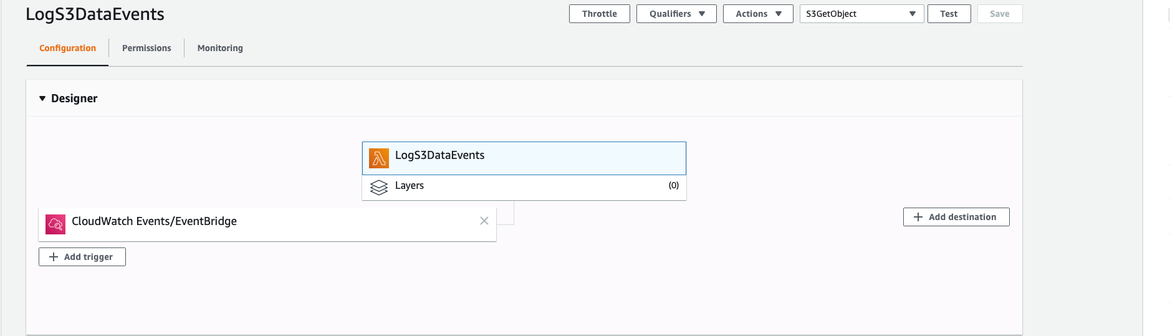
Lambda trigger configured
As the next step, you will update the function code. In our case, the chosen runtime is Python3.8:
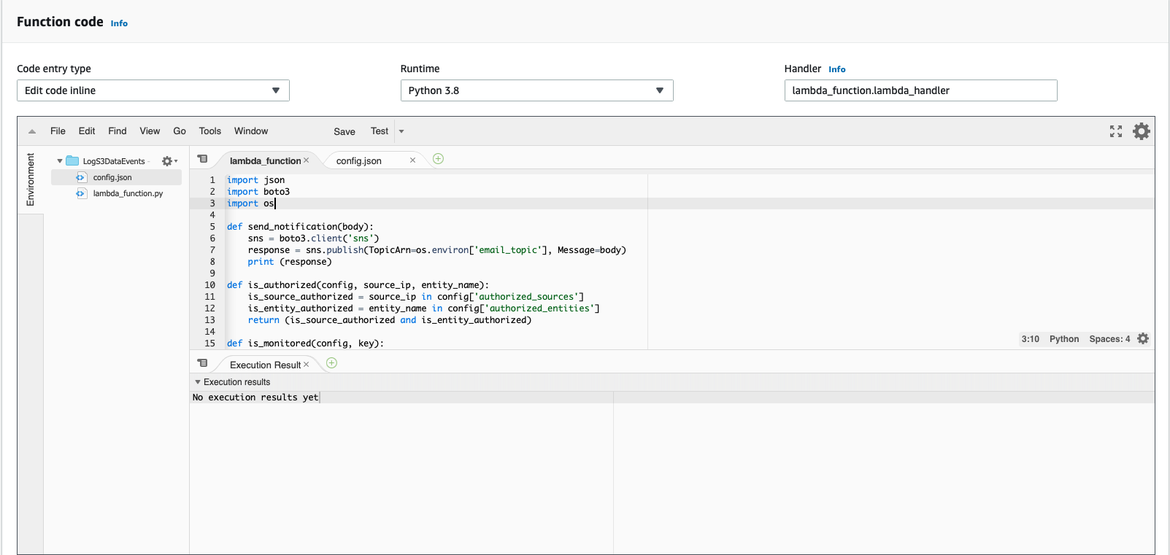
Lambda function code
We will add the following code to the lambda_function.py file:
import json
import os
import boto3
def send_notification(body):
sns = boto3.client(‘sns’)
response = sns.publish(TopicArn=os.environ[’email_topic’], Message=body)
print (response)
def is_authorized(config, source_ip, entity_name):
is_source_authorized = source_ip in config[‘authorized_sources’]
is_entity_authorized = entity_name in config[‘authorized_entities’]
return is_source_authorized and is_entity_authorized
def is_monitored(config, key):
for keyword in config[‘sensitive_filename_keywords’]:
if keyword in key:
return True
return False
def get_entity(user_identity):
if user_identity[‘type’] == ‘IAMUser’:
entity_name = user_identity[‘userName’]
entity_type = ‘User’
else:
entity_name = user_identity[‘sessionContext’][‘sessionIssuer’][‘userName’]
entity_type = ‘Role’
return entity_type, entity_name
def lambda_handler(event, context):
with open(‘config.json’, ‘r’) as fd:
config = json.load(fd)
data = event[‘detail’]
request_parameters = data[‘requestParameters’]
user_identity = data[‘userIdentity’]
source_ip = data[‘sourceIPAddress’]
access_key_id = user_identity[‘accessKeyId’]
entity_type, entity_name = get_entity(user_identity)
bucket_name = request_parameters[‘bucketName’]
key = request_parameters[‘key’]
if not is_authorized(config, source_ip, entity_name) and is_monitored(config, key):
print(‘[x] Unauthorized access detected!’)
send_notification(
‘File {} from bucket {} has been accessed by {} {} from the ip address {} using the Access Key {}’.format(
key, bucket_name, entity_type, entity_name, source_ip, access_key_id))
return {
‘statusCode’: 200
}
This code needs a support configuration file in JSON format to define which sources and entities are considered as trusted, so their accesses are not notified. Therefore, you will create a file called “config.json” as shown below:
{
"authorized_sources": ["54.153.44.90"],
"authorized_entities": ["role_with_permissions"],
"sensitive_filename_keywords": ["cardholder", "secret", "password", "credentials", "key"]
}As defined in this code snippet, access will be considered authorized exclusively when it comes from an ip address listed in the “authorized_sources” list and by an entity listed in “authorized_entities”, being notified as not authorized otherwise. Entities can be either user or role names.
def is_authorized(config, source_ip, entity_name):
is_source_authorized = source_ip in config['authorized_sources']
is_entity_authorized = entity_name in config['authorized_entities']
return (is_source_authorized and is_entity_authorized)The script also allows you to configure a subset of objects to monitor, based on a list of keywords the file names should have. Only access to those files including at least a word from the “sensitive_filename_keywords” list in its file names would be notified.
def is_monitored(config, key):
for keyword in config[sensitive_filename_keywords]:
if keyword in key:
return True
return FalseNotifications will be sent using SNS service. For the sake of simplicity, it will send an email to those recipients subscribed to a specific SNS topic. To define the SNS topic for the function, do not forget to create an environment variable called “email_topic” with the arn of the topic. At this point, it only remains to configure it.
Configuring a notification system
Last but not least, we need to configure our notification system using the SNS service. We need to create a new topic with the same name as the one configured in the Lambda function.
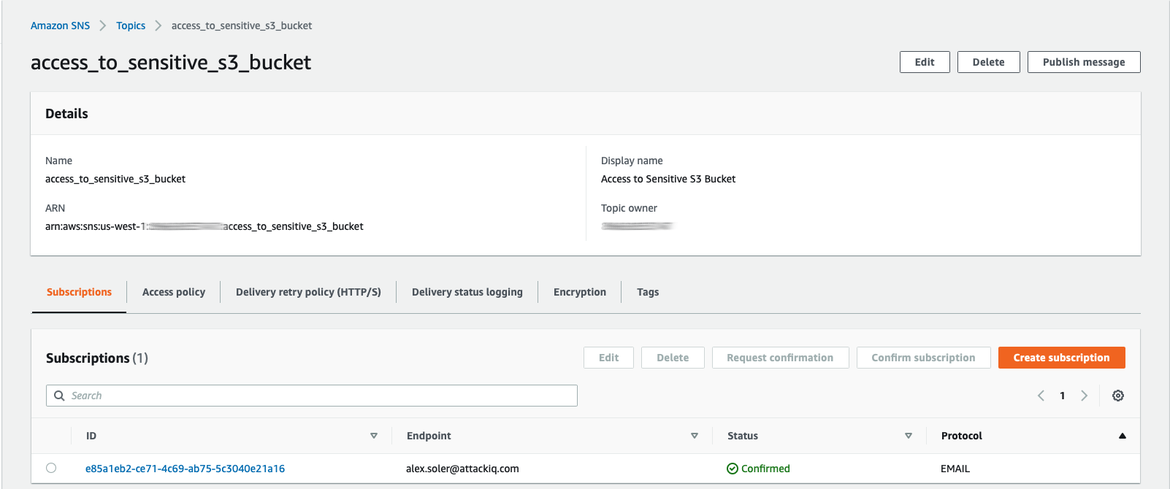
SNS subscription
In order to add new recipients to receive the notifications, we only need to create new subscriptions to this topic. The subscribed email addresses will receive an email in their inbox in order to confirm the ownership of the accounts.
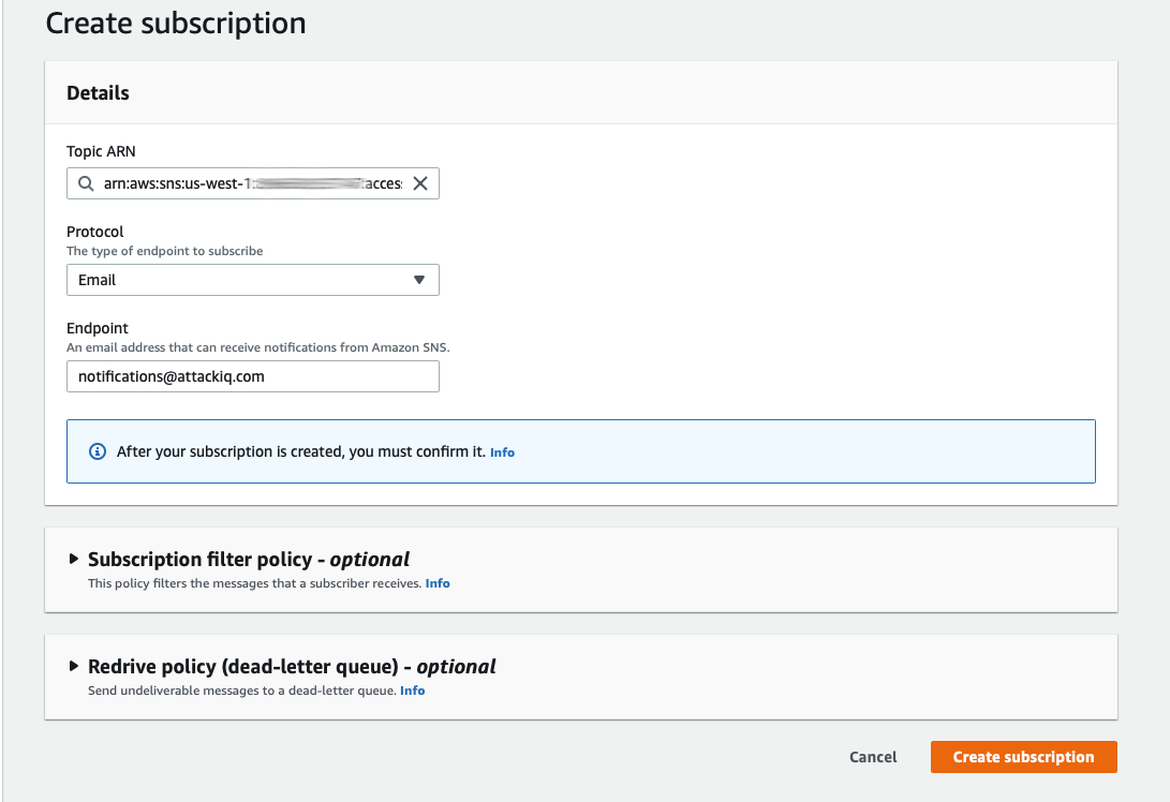
Subscription to SNS topic
We are left with just one task: trying it.
Continuous testing of our security mechanism using AIQ platform
It is time to configure an assessment to test our implemented security mechanism. Using AttackIQ Firedrill, you can configure an assessment with the scenario called Unauthorized Data Harvesting from S3 Buckets to test if any unexpected access is happening in your monitored bucket.
Thus, we have an assessment configured with two EC2 instances deployed in our target AWS account. These EC2 instances have an instance profile attached (or role) in order to have permission to access our monitored S3 bucket.
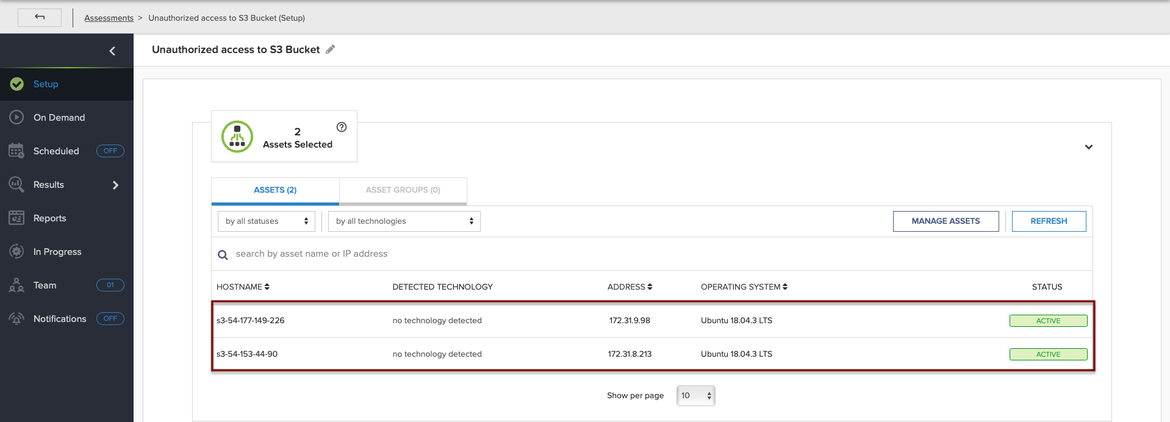
Assessment configuration
In the scenario configuration, you can define from which bucket you want to get the information, and if it is not configured, all buckets in the account will be harvested. For the sake of simplicity, we have configured the scenario to get all the information found in the bucket with the name “cg-cardholder-data-bucket-cgidlulwjvrwio”.
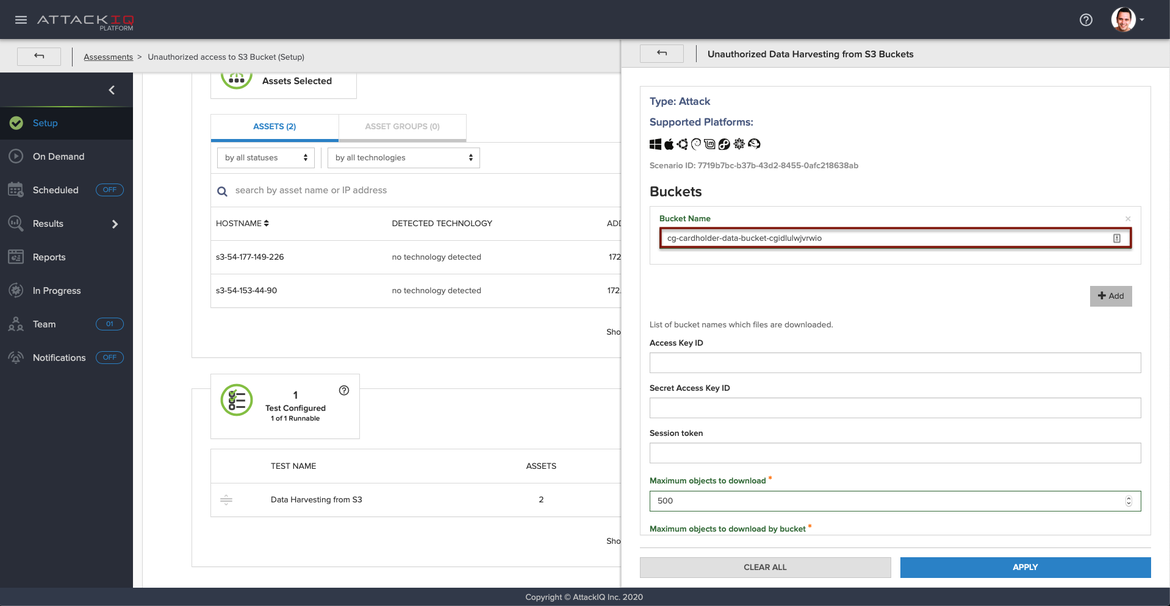
Scenario configuration
We have not configured any credentials, so the scenario will use the credentials assigned to the instance through the Metadata Service.
After diving into the assessment results, we can see the scenarios shown as “Not Prevented”, so they were able to access our sensitive information in S3. To have the scenario outcomes as “Prevented”, you will need to refine your IAM policies in order to avoid any unexpected access to your monitored S3 buckets. But this task is not always as simple as it sounds, considering the complexity of governance models in big companies.
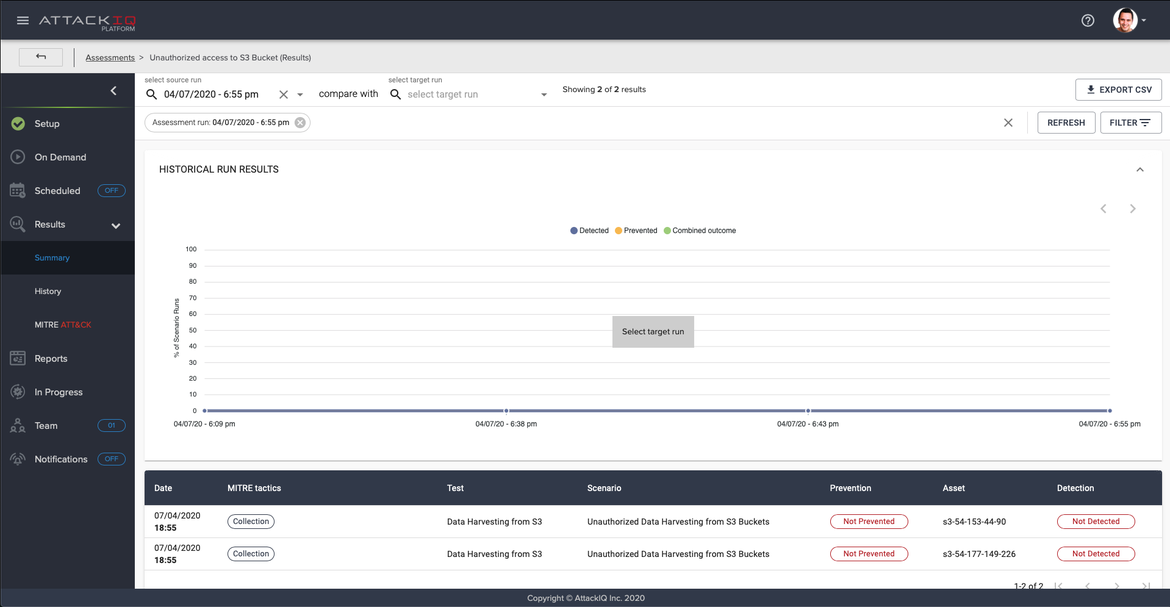
Scenario execution outcome
However, we have received a notification where it shows all the unexpected accesses that happened in our monitored S3 bucket, specifically to those files having the word “cardholder” in its filename (and only them).
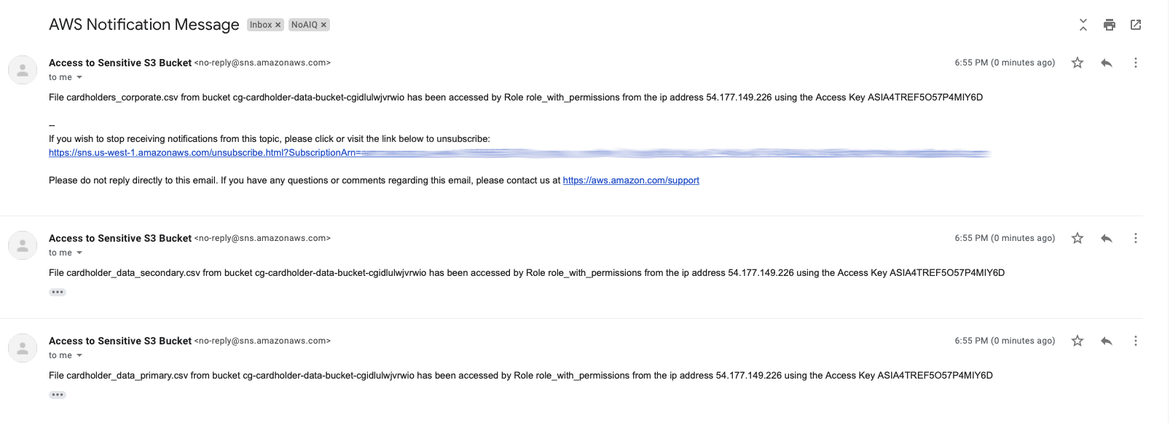
Email notifications
As you may have noticed, only those accesses coming from the IP address 54.177.149.226 have been notified. This is because the IP address 54.153.44.90 was whitelisted in our configuration file.
To Sum Up
In this blog post, we have built an access detection and notification system for sensitive data in S3 buckets.
After implementing this process you will be able to know who is accessing your sensitive information. Using this mechanism, you will be able to identify any access done to your S3 buckets by an unexpected user or from an unknown source. Therefore, catching proactively any malicious activity that could steal your information.
Besides detection, you can leverage this information to improve your IAM policies, and prevent any undesired access.
In this repository you can find a solution to automate the whole process described in this post: https://github.com/AttackIQ/audit-s3-bucket-terraform
References
- [1] Threat-Post Amazon S3 bucket data disclosure:
https://threatpost.com/leaky-amazon-s3-buckets-expose-data-of-netflix-td-bank/146084/




